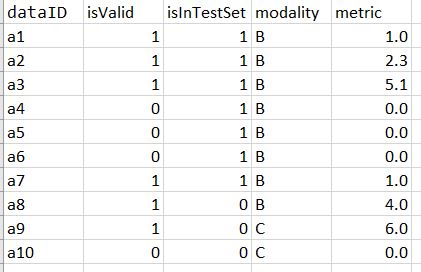
On another note, it isn’t clear to me, if isValid should be 0 or 1 for a valid entry, the filtering line at the end of the scastie checks for 0, but the filter in the for comprehension checks for 1. If there aren’t multiple types of invalid, that you need to keep, it is probably better to make isValid a Boolean and assign it with values(1).toInt == 1 (or 0, depending on which one is valid).
I’d consider applying the filtering at the Data level. This would also provide a better API for passing the predicate as an argument instead of hardwiring a single filter, e.g.
I’d also apply conversion to Data and subsequent filtering while still on the iterator, before converting to a collection. This way, in the filtering case you’ll only need to fit the filtered result items in memory rather than the full unfiltered result. Further, as there is no dependency on the result from previous computations, no flatMap/for expression is actually required…
This is good point as I’d like to apply more filtering based on other/several fields in the future.
My main concern is now how to only update filtered data in the csv file. Here is what I would like to achieve:
What I’d like to achieve is computing a metric for the valid cases (isValid = 1) only.
I have written a function to compute the metric which takes as parameter the dataID list of valid cases and once the metrics are computed for those cases, I’d like to concatenate all so that I just update those valid cases.
Ideally I’d like to keep the initial dataIDs order.
Sorry if it far from the initial post …
Please ensure that your Scastie snippets compile. Leaving out context like imports or types/classes used in the code may be easier for you, but certainly not for the reader.
DataList.filter(pred).toList
I’d prefer the variant I pasted above in this thread, though.
About the variant you talked above, what would be the function parseLine ? I tried with this one but I got error as it outputs Array[String], not Data type.
def parseLine(line: String): Data = line.split(",").map(_.trim)
In your original code you are already converting a String line to a Data instance, no? (Although there’s some room for improvement there, as well.) Extract the relevant parts and combine them in this method. What remains to be done to go from Array[String] to Data?