Below is the input dataframe:
val data = Seq( (5416, “il”, “ar”, “17/02/2017”), (5416, “ar”, “us”, “22/02/2017”), (5416, “us”, “au”, “01/03/2017”), (5416, “au”, “sg”, “03/03/2017”), (5416, “sg”, “be”, “10/03/2017”), (5416, “be”, “be”, “13/03/2017”), (5416, “be”, “ca”, “02/04/2017”), (5416, “ca”, “ch”, “16/06/2017”), (5416, “ch”, “cg”, “20/06/2017”), (5416, “cg”, “at”, “14/07/2017”), (5416, “at”, “no”, “23/07/2017”) ).toDF(“passengerId”, “from”, “to”, “date”)
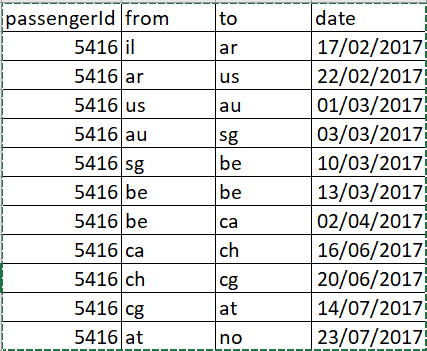
We have to group by the passenger id and get the country codes from “FROM” and “TO” columns into an array. The country code in FROM and TO are in sync with each other. Data consists of passenger travelling from one country to another on different dates
Below is the expected output:
passengerId---------------countries
5416 ------------------------[il,ar,us,au,sg,be,ca,ch,cg,at,no]
I have used the below logic:
data.groupBy(“passengerId”)
.agg(concat(collect_list(col(“from”)),collect_list(col(“to”))).name(“countries”))
It is somehow duplicating the country codes:
[“il”, “ar”, “us”, “au”, “sg”, “be”, “be”, “ca”, “ch”, “cg”, “at”, “no”, “us”, “tk”, “cl”, “pk”, “tj”, “at”, “sg”, “nl”, “tj”]