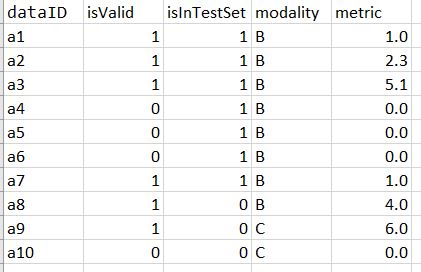
Dear all,
I’m working on a csv file and I’d like to filter and update this csv file as optimally as possible with functional programming. Here is the csv file:
I’d like to read the csv, apply filtering on it (example on isValid) before applying some function on the filtered list. Here is a code snippet:
What I’d like to achieve is computing a metric for the valid cases (isValid = 1) only at first.
I’ve written a function to compute the metric which takes as parameter the filtered dataID list of valid cases and once the metrics are computed for those cases, I’d like to update those valid cases in the initial csv. Ideally I’d like to keep the initial dataIDs order. Also, I’d like to apply other filtering later (e.g. wrt metric), so a more generic approach is appreciated.
So far, I found that I need to use copy to update the fields
Yes, this is what I’d like to do but … since I have a set of functions that call a data list as parameter, I’d like to use those functions on a filtered/unfiltered lists and concatenate the two lists (changed and unchanged) into the same csv. I am not sure though if this is the way to go.
From your code snippet, you don’t seem to handle double quotes in CSV (RFC-4180).
It’s just my opinion but I think you should use a CSV library like scala-csv or a Java CSV lib like commons-csv as your starting point. If you think enhancements can be made to the underlying CSV lib then you can submit them as Pull Requests or fork the project.
What does “I have” mean? If it’s functions you have written yourself, rework them for this use case, e.g. extract the part that processes a single Data instance to its own method and call it from the original list handling function.
Agreed in principle. However, when learning programming/a language, you have to limit yourself and start somewhere, and manually reading/writing (a limited subset of) CSV seems as good a starting point as any. Pulling in external libraries is a tradeoff IMHO - it comes with obvious benefits, but also with additional cognitive load.
@pjfanning@sangamon
Thank you all. In fact I use scala-csv for the writing but for reading I use readCsvDatabase with a case class. I am creating a small database with about 20 fields that I use as headers of the csv file.
BTW, what would be the benefit of using a Map as shown in “reader.allWithHeaders()” of https://github.com/tototoshi/scala-csv compared to using a case class to hold the values ?
Best regards,
My personal experience processing a substantial number of .csv files over dozens of projects is that the best Scala library to use kantan.csv. https://nrinaudo.github.io/kantan.csv/
Here’s my StackOverflow Answer where I attempted to implement my own Scala .csv parser (so you can see a solution). However, as the introductory note says, DO NOT USE YOUR OWN .CSV IMPLEMENTATION. There are WAY too many edge cases. And no matter how hard you try, you won’t think of them all.
If you only have simple unquoted data in columns and just want the bare minimum string matrix kind of thing without handling all the special cases of double quoting etc, I’ve made this little simplistic utility:
The code is only 200+ lines with only one principal abstraction called Grid and you can copy or be inspired by the methods for filtering and sum of numbers etc available in the Grid class.