I have another confusing issue similar to the one reported here: function already defined
Can someone help me understand the limitation?
I have three definitions of a method binSearch, each with different types. Both IntelliJ and the scala compiler complain about one of these but neither of the others. Interesting, InteliJ and scalac give different errors. Here are the definitions.
object BinarySearch {
def binSearch(left:Double, right:Double, f:Double=>Double, target:Double, threshold:Double,maxDepth:Int):Option[Double] = {
binSearch(left, right, x=>f(x)-target, threshold,maxDepth)
}
def binSearch(left:Double, right:Double, f:Double=>Double, threshold:Double ,maxDepth:Int):Option[Double] = {
???
}
def binSearch(left:Double, right:Double, f:Double=>Boolean, delta:Double, maxDepth:Int):Option[Double] = {
// takes a function, f, for which f(left) = false, and f(right) = true,
// finds an x such that f(x)=false, and f(x+threshold)= true
???
}
def main(argv:Array[String]) = {
}
}
IntelliJ complains that the call to binSearch on line 4:
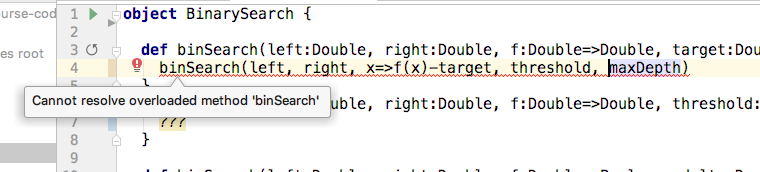
whereas, scalac, complains about a double definition.
Error:(15, 7) double definition:
def binSearch(left: Double,right: Double,f: Double => Double,threshold: Double,maxDepth: Int): Option[Double] at line 11 and
def binSearch(left: Double,right: Double,f: Double => Boolean,delta: Double,maxDepth: Int): Option[Double] at line 15
have same type after erasure: (left: Double, right: Double, f: Function1, threshold: Double, maxDepth: Int)Option
def binSearch(left:Double, right:Double, f:Double=>Boolean, delta:Double, maxDepth:Int):Option[Double] = {