Hi,
We are in the process of migrating our Scala services to Scala 3.
One of the services is relatively complex consisting of ~50K LOC.
Unfortunately, after migrating this service to Scala 3 we expirience much longer compilation times. On Scala 2.13 the service compiles in less than 30s, and its unit tests compile in ~35s.
On Scala 3.3.6 the service now compiles in ~50s, and additional ~85s for the unit tests.
I’ve used MacBook Pro on M3 CPU for the tests. The degradation in build times is much more significant on CI runners due to more limited compute resources there, which is actually the main problem for us.
So I wonder how to debug the compilation process to see if anything can be done to improve the situation. I’ve checked out (Long) compile times with Type derivation (Scala 3), and understand that most probably the issue might be related to the derivations happening during the compilation. We did switch from json4s to circe in Scala 3 version, and additionally had to migrate one small unit testing utility from Shapeless to Magnolia.
At the same time, it would be useful to get more detailed information about the compilation process. As per Scala Compiler Options | Scala Documentation and https://stackoverflow.com/a/12934208/1890318, there is -Vstatistics/ -Ystatistics flag(s), but for some reason these flag don’t work for me on Scala 3 version with SBT:
sbt:ingestion-orchestrator> set scalacOptions += "-Ystatistics"
[info] Defining scalacOptions
[info] The new value will be used by Compile / scalacOptions
[info] Reapplying settings...
[info] set current project to ingestion-orchestrator (in build file:/.../ingestion-orchestrator/)
sbt:ingestion-orchestrator> compile
[info] compiling 173 Scala sources to /.../ingestion-orchestrator/target/scala-3.3.6/classes ...
[error] bad option '-Ystatistics' was ignored
[error] one error found
[error] (Compile / compileIncremental) Compilation failed
[error] Total time: 2 s, completed Jun 10, 2025, 11:07:02 AM
Although this flag does work when I’m switching back to Scala 2.13 Git branch.
Any advice is appreciated.
Thank you in advance!
1 Like
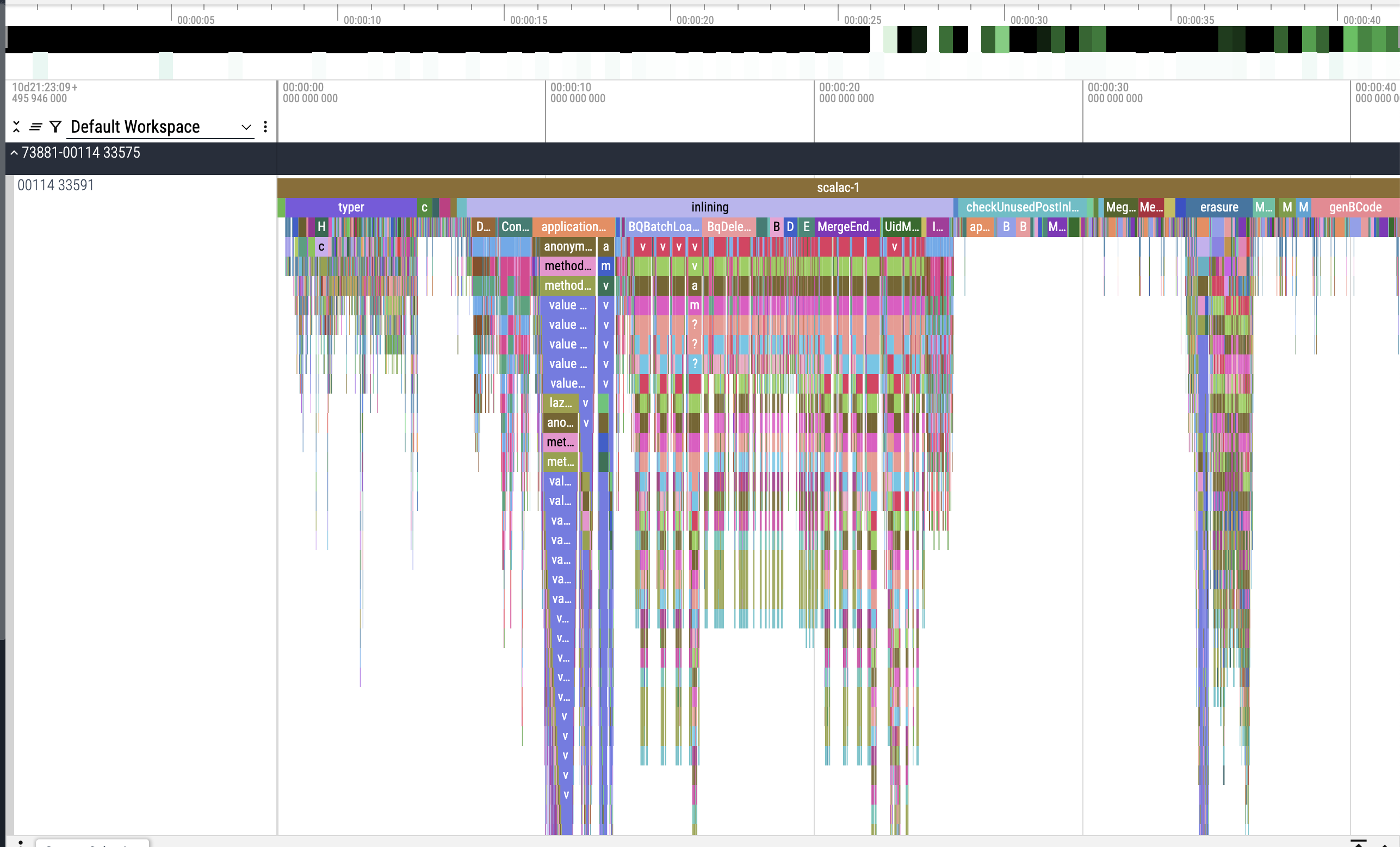
You can start with collecting traces using scalacOptions: "-Yprofile-enabled", "-Yprofile-trace:path/to/compiler.trace" It would create json file that can be opened using https://ui.perfetto.dev/ to inspect what files/classes/methods took the longest. You can do the same on Scala 2.13 and compare the results.
Circe actually has one of the worst derivation implementions when it comes to compilation times https://www.youtube.com/watch?v=M54ux51H6Fo but probably it’s something else.
What’s the other technology stack? In similar case for one of our clients it was mainly the Tapir endpoints (issue #19907 and issue #20120 ) that under new type inference took way too long, however, this one problem was already fixed in both Scala Next and backported to LTS.
Similar problems were also found with ZIO but these should also be fixed already.
For other compiler options you can try the -Vprofile flags (sources) but these were never really useful to me.
4 Likes
Hi @WojciechMazur
Thanks for the reply!
I will try to enable the profiling and see what I can get from it.
Circe actually has one of the worst derivation implementions when it comes to compilation times
Honestly, I wasn’t sure what JSON lib to use. I think json4s is great, but as I understand it wasn’t yet properly migrated to Scala 3, we were getting deprecation warnings when using it in Scala 3 version. At the same time, I’m not sure what are decent/mature alternatives to Circe in Scala 3. Maybe you could recommend something else.
What’s the other technology stack?
As a matter of fact, we also use Tapir endpoints. There are not that many of them, but this is something worth to check.
Among other things, we also use: enumeratum, pureconfig. There are quite a few other libs, but I don’t think those are worth mentioning cause those are either Java libs, or they don’t rely on derivation.
So I’ve tried generating profiling traces as per @WojciechMazur suggestion:
And from what I see, significant portion of time is indeed spent on handling Tapir endpoint sources. Also a lot of time spent on the source containing application config case classes that are being used to parse HOCON configs using pureconfig.
For pureconfig I guess I could try handling all application config case class’es tree using semi-auto derivation instead of using fully automatic derivation (which is not too convenient, but what you gonna do).
I’m not sure what to do with the Tapir endpoints though. As @WojciechMazur mentioned, this should have been already fixed. But apparently it’s still quite slow when compiling using Scala 3 LTS. I will try compiling using Scala 3.7, but I don’t have much hope it will improve the situation. Maybe I should try switching to more recent Tapir version as well.
UPDATE: As expected, using Scala 3.7 and the most recent Tapir version (namely 1.11.33) didn’t help to reduce the compilation times.
1 Like
So eventually I’ve managed to significantly reduce compilation time on Scala 3 both for main and test sources.
Before I mentioned that:
On Scala 2.13 the service compiles in less than 30s, and its unit tests compile in ~35s.
On Scala 3.3.6 the service now compiles in ~50s, and additional ~85s for the unit tests.
I’ve used MacBook Pro on M3 CPU for the tests.
Now main sources compile in ~25s, and test sources compile in ~15s.
In short, to solve this, I had to review the entire codebase and to make sure there is no redundant autoderivation.
In particular:
- For unit tests we’ve implemented a utility type class autoderivation that allows automatically generating random/default instances for basically any
case class. This utility is based on Magnolia (for Scala 2, it was implemented using Shapeless). Here is an exceprt from its implementation to get the hint how it works:
import magnolia1.*
trait DefaultRandom[T]:
def default: T
def random: T
object DefaultRandom extends AutoDerivation[DefaultRandom]:
def join[T](ctx: CaseClass[DefaultRandom, T]): DefaultRandom[T] =
new DefaultRandom[T]:
def default: T = ctx.construct { param =>
param.typeclass.default
}
def random: T = ctx.construct { param =>
param.typeclass.random
}
/** chooses which subtype to delegate to */
def split[T](ctx: SealedTrait[DefaultRandom, T]): DefaultRandom[T] =
new DefaultRandom[T]:
// default will be always first subclass alphabetically
def default: T = ctx.subtypes.head.typeclass.default
def random: T = ctx.subtypes(scala.util.Random.nextInt(ctx.subtypes.size)).typeclass.random
This utility is being used all over the test classes, and apparently this is what caused the slow compilation of tests. As a workaround I’ve moved derivations of DefaultRandom[T] instances for all relevant case class under a single object to make sure the derivation for the same type won’t happen twice. Now the tests just import “prederived” instances DefaultRandom instead of triggering derivation “in-place”.
- As mentioned above, we use Tapir, and profiling has shown that much time is spent on compiling Tapir endpoints. To solve this I had to switch to semi-auto derivation of Tapir
Schema instances.
- Similarly, I had to get rid of autoderivation for Circe
Codec’s and switch to semi-auto derivation.
Generally such approach requires manually writing a lot of semi-auto derivation calls (since we have a lot of different case classes).
But I’m happy with the resulting compilation times, taking into account that it’s now on par or even better than Scala 2 version of the service.
@WojciechMazur thank you again for the hints!
7 Likes
Tangential musing: this leads me to wonder (not for the first time) if we can/should somehow formally discourage the use of full-auto derivation amongst the Scala community.
It’s wondrously powerful, and it’s really easy for projects to adopt it whole-heartedly (certainly I did so in my earlier days), but it seems to pretty consistently be a footgun (especially for projects that wind up larger) precisely because it tends to explode compile times like this. It’s a short-term win because of the boilerplate reduction, but a long-term lose because of all the seconds you waste waiting for compilation.
Especially given that Scala 3 has reduced the boilerplate for semi-auto derivation to a pretty minimal level, I’m increasingly suspecting that full-auto is basically always a mistake nowadays.
3 Likes
@jducoeur taking into account the current state of things, I do agree. I would say it probably makes sense to warn about auto-derivation performance caveats in Scala 3 docs (unless such warnings are already in place, and I just missed them), as well as in the library docs relying on the derivation.
At the same time, it’s still important to point out that we faced these performance issues only after migrating to Scala 3.
And it’s not particular to Circe or Tapir derivation. Our DefaultRandom utility provided good-enough performance with Scala 2 and Shapeless, and only after migrating it to Scala 3 and Magnolia I had to resort to the workaround described above.
I’m no Scala Metaprogramming expert, but this makes me wonder what are the root causes: is it something related to the fundamental design choices made for Scala 3 Metaprogramming, or is it some kind of inefficiency in Magnolia? And is there a room for performance improvement within Scala 3 Metaprogramming implementation itself.
I guess only someone with good expertise in this topic can answer these questions.
I’m no Scala Metaprogramming expert, but this makes me wonder what are the root causes: is it something related to the fundamental design choices made for Scala 3 Metaprogramming, or is it some kind of inefficiency in Magnolia? And is there a room for performance improvement within Scala 3 Metaprogramming implementation itself.
I answered all these questions in the presentation that @WojciechMazur linked to 
If we wanted to discuss the reasons, are:
- implicit search is expensive: every time an implicit of type
X is requested compiler looks: to the current scope and companion object of every type that appears in the type X - e.g. for X=TypeClass[Foo[Bar, SomeObject.Baz]] compiler would look into objects TypeClass, Foo, Bar, SomeObject, SomeObject.Baz. Additionally, for blackbox macros/inline defs compiler needs only to analyze type signatures to determine whether implicit is a valid candidate, if macro is picked and then its failure fails implicit search. Whitebox macros/transparent inline defs need to be expanded (if no implicit with higher priority matches) and macro failure would make the implicit search continue testing various options (so it should be used as a fallback or you will always attempt to expand it, fail and then use some other implicit).
- “caching” the results of the derivation in some implicits by hand - semi-automatic derivation - means that matching solution can be found in the scope, before falling back on companion lookups and a lot of type tests would make it more expensive
- for that reason automatic derivation was discouraged for years
- however it can be made as cheap (*) as semi-automatic derivation if the derivation logic would only use implicits for overriding the defaults, and having the default implementations being handled by a single macro, that handles recursion in data with recursion in macro (also allowing for more optimal runtime performance)
- some non-hypothetical examples:
- Jsoniter allows recursive semi-automatic derivation and it’s one the the factors that let it run rings Circe
- Chimney generates recursive data-mapping transformation without visible compile-time nor runtime overhead
- additionally when it comes to Magnolia:
- on Scala 2 was implemented with macros, it is very fast, for a while it boasted the fastest derivation (outside of implementing everything in macros yourself)
- on Scala 3 was implemented with Mirrors which (the way most people use them) are slower than Shapeless on Scala 2, but Magnolia adds its own overhead, so automatic derivation with Magnolia dived from the fastest to the slowest. For bigger derivations it can be painfully slow.
- however as a redeeming quality, semiautomatic derivation with Magnolia can have better runtime performance, since Magnolia’s data structures “caches” intermediate results rather than inlining them - for large, nested case classes “naive” big inlines can results with methods that exceed the bytecode limit under which JVM considers code eligible for compilation - and always interprets which can be a few hundred times slower
(*) - if you are using the result once, if you need to use it multiple times, automatic derivation would derive multiple times, and even putting compilation times aside we cannot guarantee that it would result in the same behavior in every instance.
IMHO issues with automatic derivation are an artifact on reliance on Shapeless/Mirrors-based approach which, again IMHO, offers nice learning curve but PoC-at-best results:
- error messages are impenetrable for newcomers
- debugging requires basically manual binary search with adding/commenting out intermediate implicits
- materializing every single intermediate result as a new instance, with additional allocation, obligatory instance for every primitive type and going through intermediate product representations (
HList/Coproduct on Scala 2 + Shapeless, tuples on Scala 3).
If you handle everything recursively in a macro, well, it’s a pain for the maintainers, but users can finally have some good errors messages, quick compilation and decent runtime performance. And you can write automatic derivation that performs so well, that the only reason for using (recursive) semiauto is ensuring the the same behavior in multiple places.
2 Likes
Thank you @MateuszKubuszok, that’s quite comprehensive explanation. I think it will be invaluable for people that will face the same issues in future.
P.S. Regarding
I answered all these questions in the presentation that @WojciechMazur linked to
Yeah, I must admit that I didn’t watch it yet 
It could be interesting to also have a comparison against Scala 2 with the same code changes.
This is actually something that’s covered by @MateuszKubuszok’s presentation linked earlier.
Apparently the difference between automatic and semiautomatic derivation is not that significant on Scala 2.