@jimka:
Weren’t you creating BddNodes in a way that ensures uniqueness of label field? In such case you can simplify the code:
case class BddNode(label:Int, positive:Bdd, negative:Bdd) extends Bdd {
override def equals(that: Any): Boolean = {
that match {
case b: Bdd => this eq b
case _ => false
}
}
override def hashCode(): Int =
label * some_prime // multiply by a big prime to improve distribution
}
The issue with System.identityHashCode is that it is guranteed to be stable in Java specification, but object’s address doesn’t, so JVM needs to have a map of Object address -> hash code as the address of an object can change (garbage collector can and often does move the objects around). This map takes up memory and also lookup could be costly compared to just accessing label field. This map’s contents are also lazily created so if you don’t invoke System.identityHashCode then you don’t pay the price of mapping your object to identity hash code.
@tarsa no, label is not a unique identifier.
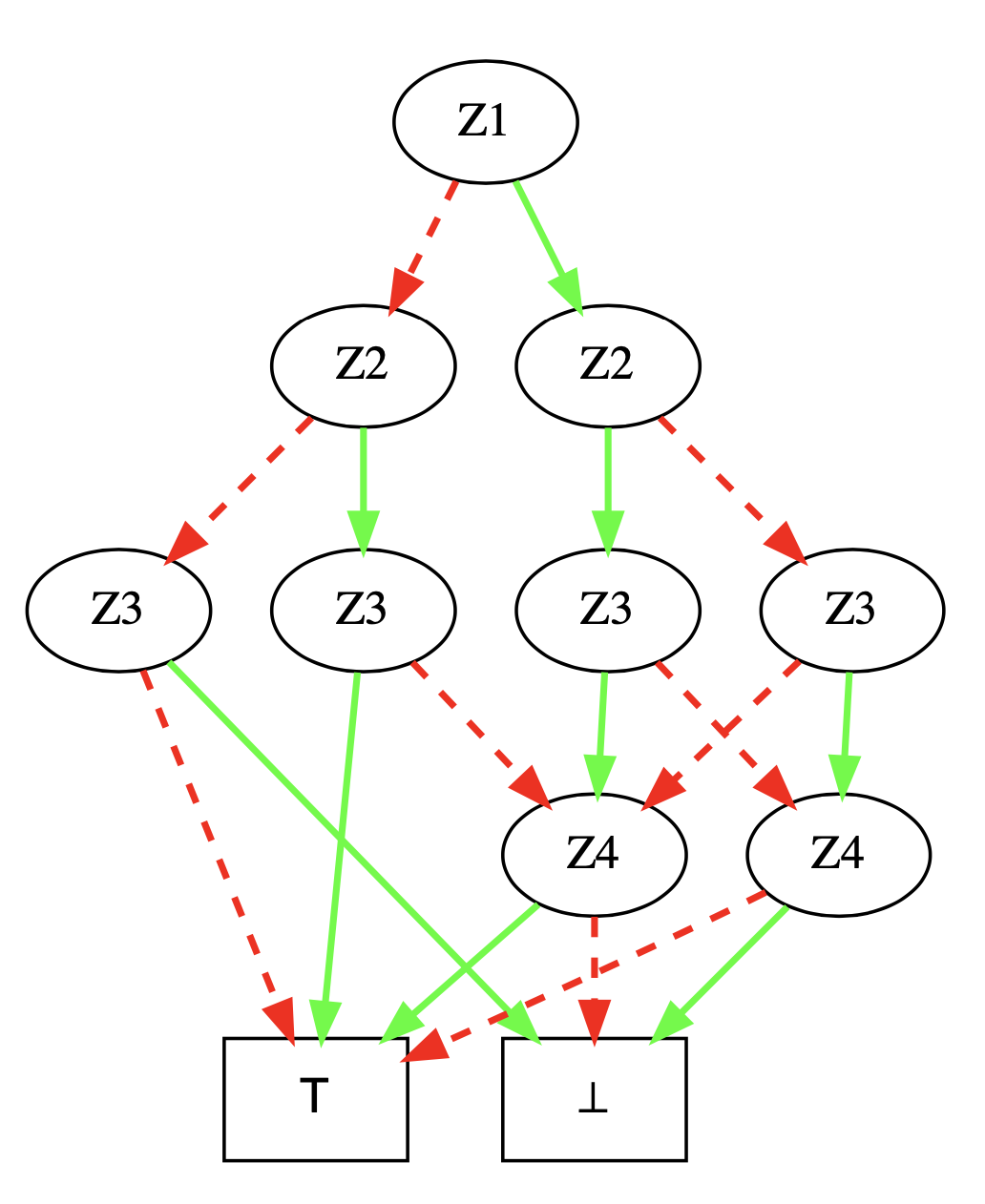
Here is an image of what such a structure looks like. As you can see many nodes have the same label: Z1, Z2, Z3, Z4. But a node is uniquely identified by its label+positiveChild+negativeChild
What is the purpose of System.identityHashCode if it cannot be reliably used as a hash-code? This seems strange to me, like I’m perhaps not understanding something fundamental. Do Maps work? Do they use identityHashCode internally?
It is reliable. What @tarsa said is that identityHashCode consumes more memory, but only after first usage (it is lazy), and therefore it would have been better if the Bdds had a unique identifier in the first place (but they don’t).
Is it possible in Scala to decrease the size of an object containing an Integer by promising that the integer will always between 0 and 256 exclusive? exponentially many wasted bytes is expensive. Typically this type of optimization is only available in C-like languages.
java.lang.Integer in Java 8 implements some unsigned operations: compareUnsigned, divideUnsigned, remainderUnsigned, parseUnsigned, toUnsignedString. Addition, subtraction and multiplication don’t need unsigned equivalents because in two’s complement encoding they work the same.
There are always some issues when doing operation on mixed signedness types. Rust language forces you to cast numbers to matching types before doing operations, but that’s rather cheap syntactically (e.g. something as i32, something_else as u32). Also unsigned types are source of mistakes if you e.g. count down to zero and have some off-by-1 error in counting somewhere. It’s easier to avoid mistakes with signed types.
As to numeric types ranges and bit sizes, they’re pretty standard.
Byte takes 1 byte and has range -(2^7) to (2^7)- 1
Short takes 2 bytes and has range -(2^15) to (2^15)- 1
Int takes 4 bytes and has range -(2^31) to (2^31)- 1
Long takes 8 bytes and has range -(2^63) to (2^63)- 1
I think pretending they are unsigned won’t work in my application, because I’m already punning on negativeness. In my application an integer such as 7 represents the Boolean variable x_7 and -1 represents the logical complement of x_7. That being said, I am considering the consequences of giving up that notational convenience to experiment with using Byte. As I’ve said elsewhere my structures are exponentially explosive in size, so every little bit of size savings could have a tremendous positive effect and is worth investigating.
I laughed. I remember learning 6502 assembly in 1985, where signed bytes were heavily used. For example to represent a relative-jump backwards. Not sure whether modern processors care about representing jump distance in 8 bits???
MOS Technology 6502 was an 8-bit processor. Most processors today are 64-bits.
I’m actually wondering, now that most processors are 64-bit, does it make sense to always use 64-bit data types like Long and Double, or does using smaller data types like Float and Int still gain something?
Good question, If I use a data structure (an instance of some class) whose size is 20 bytes (in my case two 64 bit pointers and a Short), does it get aligned on an 8 byte grid thus taking the same space as 3 pointers?
Objects are usually (i.e. I think virtually always on 64-bit platforms) aligned on 8-byte boundary, so if your objects’ size is not a multiple of 8 bytes then it’s padded. OTOH if you have e.g. 4 shorts in a single object (as fields) then they occupy 8 bytes in total.
As Tarsa said, memory footprint is the main reason, not only for main memory, but also cache and registers. You will have higher performance if you can stuff more stuff in your CPU caches, and have more registers available for computations, even if the CPU operations are not more costly.
 Not sure if it is useful for my applications to have integers from 1 to 127.
Not sure if it is useful for my applications to have integers from 1 to 127.